
[빅분기 실기] 04. 데이터 전처리 필살기: 결측치, 이상치, 중복값 완벽하게 처리하기 (Python)
설명: 빅데이터분석기사 실기 1유형의 핵심! 타이타닉 데이터셋을 활용해 결측치 대체/제거, IQR 및 Z-score 기반 이상치 탐지, 중복값 제거 등 데이터 전처리 필수 기법을 파이썬 코드로 정리합니다.
주요 키워드: 빅데이터분석기사 실기, 데이터 전처리, 결측치 처리, 이상치 제거, IQR 공식, Z-score, 파이썬 데이터 분석
안녕하세요 박박사입니다.
지난 포스팅에서는 데이터 전처리의 기초인 인덱싱과 슬라이싱을 다뤄보았습니다.
오늘은 빅분기 실기 1유형의 단골 손님이자 득점 포인트인 '결측치, 이상치, 중복값 처리'에 대해 심층적으로 알아보겠습니다.
현장 시험에서는 특정 변수의 결측치를 중앙값으로 대체한 후 평균을 구하거나, 이상치를 제거한 후 데이터의 개수를 묻는 문제가 자주 출제됩니다. 오늘 내용을 완벽히 이해하시면 1유형 1~2문제는 거뜬히 맞히실 수 있습니다!
1. 데이터 불러오기 및 구조 확인
분석에 앞서 전처리를 연습하기 가장 좋은 titanic 데이터셋을 불러오겠습니다.
import seaborn as sns
import pandas as pd
# 1. 타이타닉 데이터 불러오기
df = sns.load_dataset('titanic')
# 데이터 상위 5행 확인
print(df.head())
# 데이터 구조(행, 열) 확인
print(df.shape)
# 변수 타입 및 결측치 존재 여부 확인
print(df.info())
- y(종속변수): survived (0: 사망, 1: 생존)
- x(독립변수): pclass(객실 등급), sex(성별), age(나이) 등

2. 결측치(Missing Value) 처리
데이터에 값이 비어있는 결측치는 분석 결과를 왜곡합니다. 시험에서는 제거하거나 특정 값으로 대체하는 능력을 요구합니다.
(1) 결측치 확인 및 제거
# 결측치 개수 확인
print(df.isnull().sum())
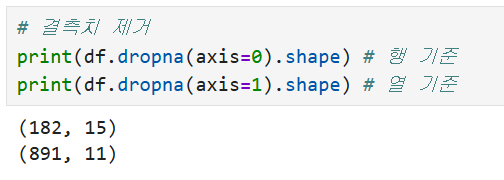
# 행 기준 제거 (결측치가 하나라도 있는 행은 삭제)
df_drop_row = df.dropna(axis=0)
print("행 제거 후 형상:", df_drop_row.shape)
# 열 기준 제거 (결측치가 있는 변수 자체를 삭제)
df_drop_col = df.dropna(axis=1)
print("열 제거 후 형상:", df_drop_col.shape)

(2) 결측치 대체 (평균값/중앙값)
시험에서는 보통 "age의 결측치를 중앙값으로 채운 후 ~를 계산하라"는 식으로 출제됩니다.
# 원본 보호를 위한 복사
df2 = df.copy()
# 1. 중앙값 계산
median_age = df2['age'].median()
print(f"Age의 중앙값: {median_age}")
# 2. 결측치 대체
df2['age'] = df2['age'].fillna(median_age)
# 3. 대체 후 결측치 및 평균 변화 확인
print("대체 후 age 결측치 수:", df2['age'].isnull().sum())
print("원본 age 평균:", df['age'].mean())
print("대체 후 age 평균:", df2['age'].mean())


💡 빅분기 실기 Point!
결측치를 채우기 전과 후의 평균이나 표준편차의 변화량을 묻는 문제가 나올 수 있으니, fillna() 적용 전후의 기초 통계량을 확인하는 습관을 들이세요.
3. 이상치(Outlier) 확인 및 처리
이상치는 데이터의 전체적인 경향에서 크게 벗어난 값입니다. 시험에서 가장 많이 나오는 두 가지 기준을 마스터해 봅시다.
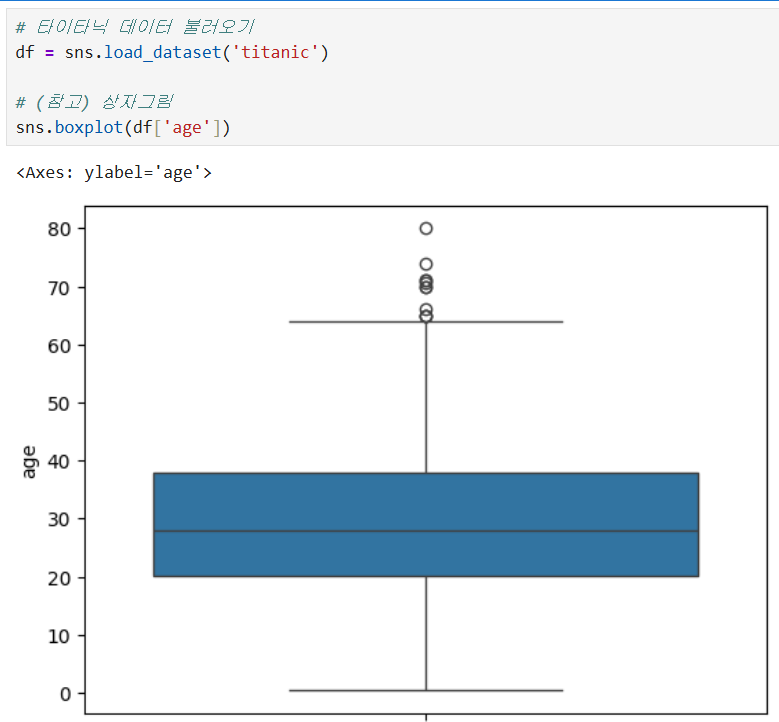
(1) IQR(Interquartile Range) 방식
상자그림(Boxplot)의 원리를 이용한 방법입니다. Q1, Q3로부터 1.5 * IQR을 벗어나는 값을 이상치로 간주합니다.
# Q1, Q3, IQR 구하기
Q1 = df['age'].quantile(0.25)
Q3 = df['age'].quantile(0.75)
IQR = Q3 - Q1
# 경계값 설정
upper = Q3 + 1.5 * IQR
lower = Q1 - 1.5 * IQR
print(f"상한선: {upper}, 하한선: {lower}")
# 문제: age 변수의 이상치를 제외한 데이터 수는?
cond1 = (df['age'] <= upper)
cond2 = (df['age'] >= lower)
# 두 조건을 모두 만족하는 데이터 필터링
df_new = df[cond1 & cond2]
print("이상치 제외 후 데이터 수:", len(df_new))


(2) 표준정규분포(Z-score) 방식
데이터가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 계산합니다. 보통 ±3Z를 벗어나면 이상치로 봅니다.
# Z-score 계산: (데이터 - 평균) / 표준편차
mean_age = df['age'].mean()
std_age = df['age'].std()
znorm = (df['age'] - mean_age) / std_age
# 문제 : 이상치의 개수는 몇 개인가? (± 3Z 기준)
cond_upper = (znorm > 3)
cond_lower = (znorm < -3)
outlier_count = len(df[cond_upper]) + len(df[cond_lower])
print(f"Z-score 기준 이상치 개수: {outlier_count}개")

4. 중복값(Duplicate) 제거
분석의 정확도를 위해 중복된 행은 제거해야 합니다.
# 데이터 복사
df_dup = df.copy()
# 중복 제거 전 shape
print("제거 전:", df_dup.shape)
# 중복값 제거 (첫 번째 행만 남기고 삭제)
df_dup = df_dup.drop_duplicates()
# 중복 제거 후 shape
print("제거 후:", df_dup.shape)

🚩 빅분기 실기 시험 핵심 요약
- 결측치 확인: df.isnull().sum()으로 변수별 결측치 개수를 먼저 파악하세요.
- IQR 공식 암기:(실기 시험장에서 직접 계산 코드를 작성해야 합니다).

- 필터링: 여러 조건을 결합할 때는 (조건1) & (조건2) 형태와 소괄호 사용에 주의하세요.
- 수치 비교: 전처리 전후의 mean(), std(), count() 차이를 구하는 연습을 반복하세요.
다음 포스팅에서는 데이터 변환(Scaling) 및 인코딩(Encoding) 방법에 대해 알아보겠습니다. 궁금한 점은 댓글로 남겨주세요!
#빅데이터분석기사 #빅분기실기 #데이터전처리 #파이썬데이터분석 #결측치처리 #이상치제거 #IQR #Zscore #Pandas #Seaborn
https://intjpark.tistory.com/55
[빅분기 실기] 1유형 데이터 다루기 마스터하기
2026 빅데이터분석기사 실기 1유형 완벽 대비! Pandas 전처리, 기초 통계, 그룹연산, 시각화까지 30점 만점 받는 핵심 전략과 실전 코드 예제를 한 번에 정리했습니다. 실기 시험 직전 복습용으로 최
intjpark.tistory.com
https://intjpark.tistory.com/56
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (2) - 필터링, 정렬, 조건부 수정
빅데이터분석기사 실기 1유형 | mtcars로 배우는 필터링·정렬·np.where 파이썬 실습빅데이터분석기사 실기 1유형 대비를 위해 mtcars 데이터셋으로 파이썬 필터링, 정렬, np.where 활용법을 예제 코드와
intjpark.tistory.com
'빅데이터분석기사 실기 | 작업형 1·2·3' 카테고리의 다른 글
| [빅분기 실기] 2유형 (2) 모델링 및 성능평가, 예측값 제출 (0) | 2026.01.22 |
|---|---|
| [빅분기 실기] 2유형 (1) 데이터 전처리, EDA, 모델선정 (0) | 2026.01.21 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (4) 데이터 스케일링, 결합, 그리고 날짜 데이터 처리 (0) | 2026.01.19 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (2) - 필터링, 정렬, 조건부 수정 (0) | 2026.01.14 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (0) | 2026.01.13 |



