
- 주제: 빅데이터분석기사 실기 1유형 대비 데이터 전처리 마스터 (4편)
- 핵심 내용: 데이터 스케일링(표준화/정규화), 데이터 결합(pd.concat), 날짜 및 시간 데이터 처리 기법
- 목표: 실기 시험에서 자주 출제되는 데이터 변형 및 시간 필터링 패턴 완벽 습득
[빅분기 실기] 1유형 마스터 #4. 데이터 스케일링, 결합, 그리고 날짜 데이터 처리
안녕하세요 박박사 입니다! 빅데이터분석기사(빅분기) 실기 합격을 위한 데이터 핸들링 네 번째 시간입니다.
지난 포스팅에 이어 오늘은 데이터의 단위를 맞추는 스케일링, 흩어진 데이터를 하나로 합치는 결합, 그리고 시험에서 빠지지 않고 등장하는 날짜 데이터 다루기를 배워보겠습니다.
1유형 점수를 결정짓는 핵심 구간이니 집중해서 따라와 주세요!
5. 데이터 Scaling (데이터 표준화, 정규화)
데이터의 변수마다 단위(Unit)가 다르면 모델 성능에 영향을 줄 수 있습니다. 이를 해결하기 위해 값을 일정 범위로 맞추는 작업이 필요합니다.
1) 데이터 표준화 (Standardization)
Z-Score라고도 하며, 평균을 0, 표준편차를 1로 만듭니다.
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
df = pd.read_csv('mtcars.csv')
# StandardScaler 활용
zscaler = StandardScaler()
df['zscore'] = zscaler.fit_transform(df[['mpg']])
# 확인: 평균은 0에 수렴, 표준편차는 1이 됨
print(df['zscore'].mean(), df['zscore'].std())


💡 직접 계산 방식 (시험에서 원리를 물을 때 유용)
실기 시험에서는 가끔 라이브러리 없이 수식으로 계산하라는 요구가 있을 수 있습니다.
std = df['mpg'].std()
mean_mpg = df['mpg'].mean()
df['zscore_self'] = (df['mpg'] - mean_mpg) / std
print(df['zscore_self'].mean(), df['zscore_self'].std())


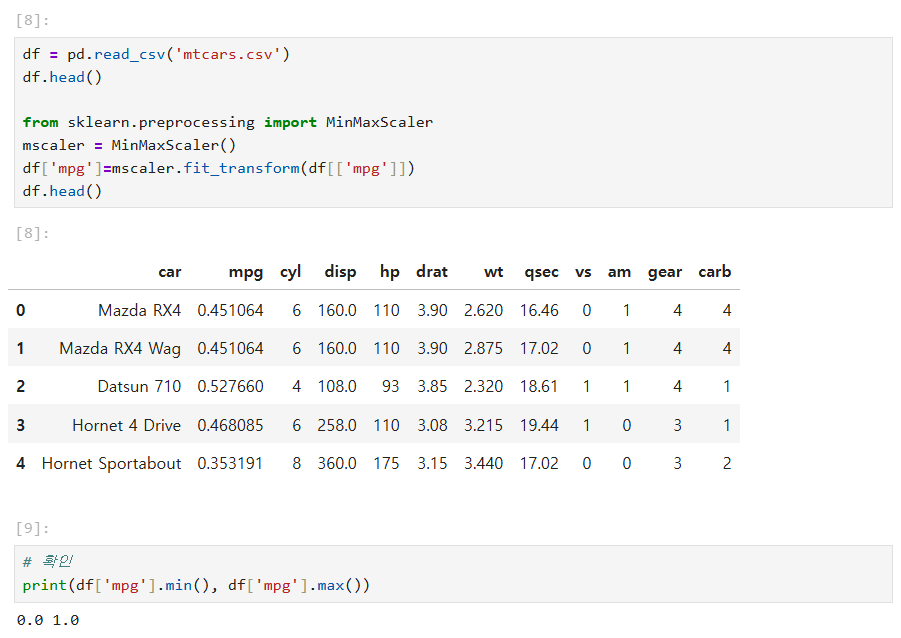
2) 데이터 정규화 (Min-Max Normalization)
데이터를 0과 1 사이의 값으로 변환합니다.
from sklearn.preprocessing import MinMaxScaler
mscaler = MinMaxScaler()
df['mpg_minmax'] = mscaler.fit_transform(df[['mpg']])
# 확인: 최소값 0, 최대값 1
print(df['mpg_minmax'].min(), df['mpg_minmax'].max())
🚩 출제포인트: > * StandardScaler: 이상치가 많은 데이터에 유리합니다.
- MinMaxScaler: 데이터의 분포를 알 수 없거나, 특정 범위 내로 한정해야 할 때 사용합니다. 시험에서는 주로 "0~1 사이 값으로 변환하라"는 지문으로 출제됩니다.
6. 데이터 합치기 (Data Merging)
여러 개로 나누어진 데이터를 행(Row)이나 열(Column) 방향으로 합칠 때는 pd.concat을 사용합니다.
import seaborn as sns
df = sns.load_dataset('iris')
# 1) 행 방향 결합 (위 + 아래)
df1 = df.loc[0:30, ]
df2 = df.loc[31:60, ]
df_sum_row = pd.concat([df1, df2], axis=0)
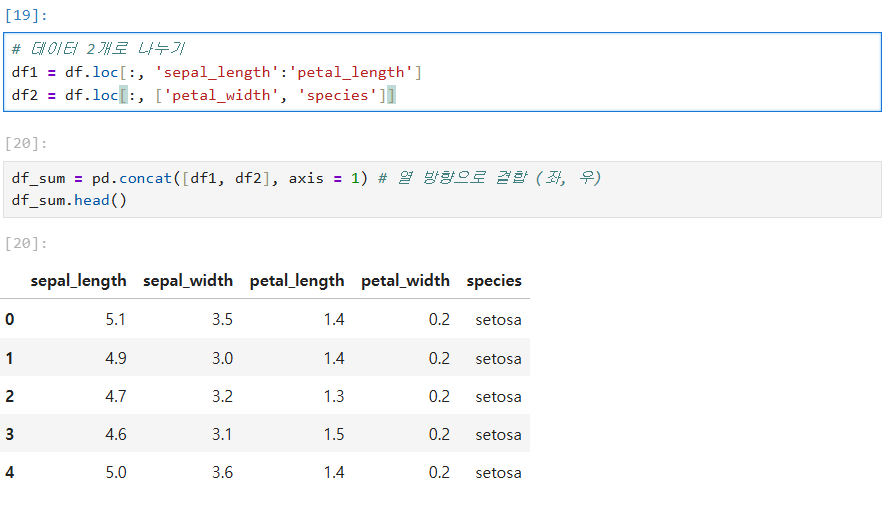
# 2) 열 방향 결합 (좌 + 우)
df_col1 = df.loc[:, 'sepal_length':'petal_length']
df_col2 = df.loc[:, ['petal_width', 'species']]
df_sum_col = pd.concat([df_col1, df_col2], axis=1)
print(df_sum_row.shape, df_sum_col.shape)



7. 날짜/시간 데이터 및 Index 다루기
빅분기 실기 1유형에서 "특정 연도/월의 합계를 구하라"는 문제는 거의 매회 출제됩니다. 날짜 타입 변환은 필수입니다!
1) datetime 변환과 컬럼 분리
문자열로 된 날짜 데이터를 파이썬이 인식할 수 있는 날짜 객체로 바꿉니다.
# 데이터 생성
df = pd.DataFrame({
'날짜': ['20220103','20220105', '20230105','20230127','20220203', '20220205'],
'판매수': [3, 5, 5, 10, 10, 10]
})
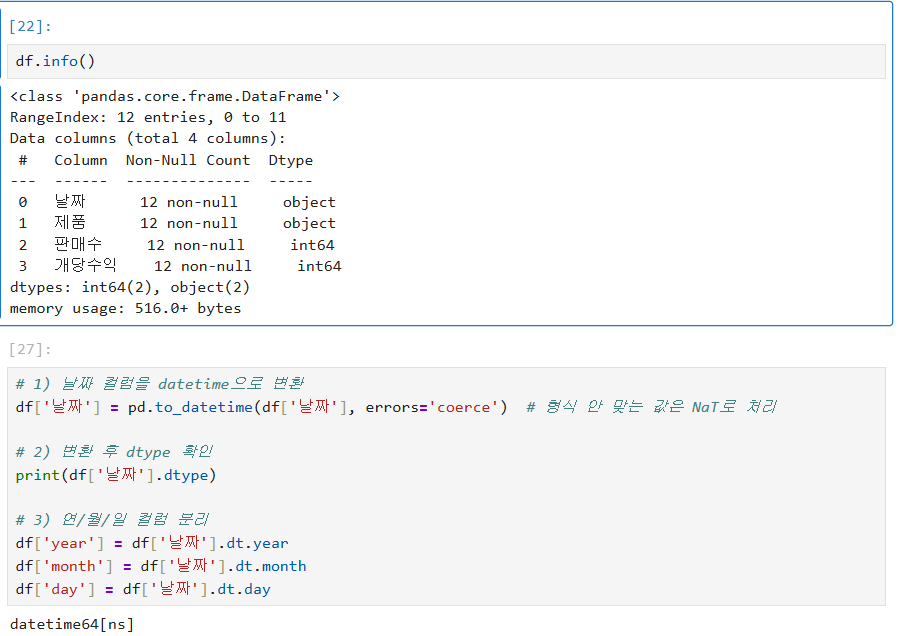
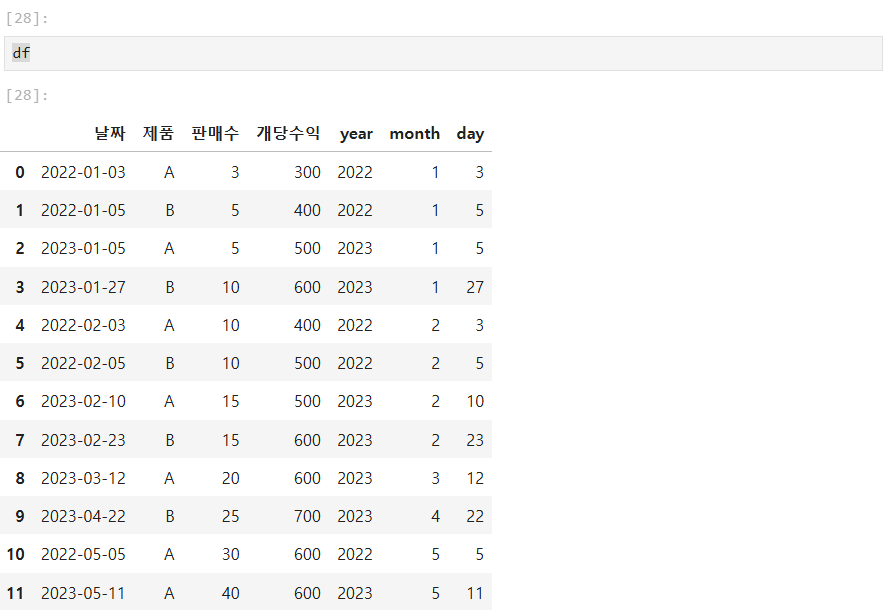
# datetime으로 변환 (errors='coerce'는 에러 발생 시 NaT 처리)
df['날짜'] = pd.to_datetime(df['날짜'], errors='coerce')
# 연/월/일 추출
df['year'] = df['날짜'].dt.year
df['month'] = df['날짜'].dt.month
df['day'] = df['날짜'].dt.day
print(df.head())

2) 날짜 구간 필터링
between 함수를 사용하면 특정 기간의 데이터만 쉽게 뽑아낼 수 있습니다.
# 2023년 1월 1일부터 2월 23일까지의 데이터만 필터링
result = df[df['날짜'].between('2023-01-01', '2023-02-23')]
print(result)
🚩 출제포인트: > 시험장에서는 데이터가 '2023-01-01' 형태일 수도 있고 '2023/01/01'일 수도 있습니다. pd.to_datetime은 웬만한 형식은 자동으로 인식하므로 당황하지 말고 변환부터 하세요!
마무리하며
오늘은 데이터의 스케일을 조정하고, 합치고, 시간 데이터를 요리하는 방법을 배웠습니다. 특히 날짜 데이터 추출(dt.year, dt.month)은 1유형 단골 문제이니 꼭 손으로 직접 코드를 쳐보시기 바랍니다.
다음 포스팅에서는 데이터 그룹화(groupby)와 정렬(sort_values)을 활용한 심화 문제 풀이를 다루어 보겠습니다.
궁금한 점은 댓글로 남겨주세요! 여러분의 합격을 응원합니다!
도움이 되셨다면 공감과 구독 부탁드립니다! :)
https://intjpark.tistory.com/55
[빅분기 실기] 1유형 데이터 다루기 마스터하기
2026 빅데이터분석기사 실기 1유형 완벽 대비! Pandas 전처리, 기초 통계, 그룹연산, 시각화까지 30점 만점 받는 핵심 전략과 실전 코드 예제를 한 번에 정리했습니다. 실기 시험 직전 복습용으로 최
intjpark.tistory.com
https://intjpark.tistory.com/56
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (2) - 필터링, 정렬, 조건부 수정
빅데이터분석기사 실기 1유형 | mtcars로 배우는 필터링·정렬·np.where 파이썬 실습빅데이터분석기사 실기 1유형 대비를 위해 mtcars 데이터셋으로 파이썬 필터링, 정렬, np.where 활용법을 예제 코드와
intjpark.tistory.com
https://intjpark.tistory.com/58
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (3) - 결측치, 이상치, 중복값 완벽하게 처리하기
[빅분기 실기] 04. 데이터 전처리 필살기: 결측치, 이상치, 중복값 완벽하게 처리하기 (Python)설명: 빅데이터분석기사 실기 1유형의 핵심! 타이타닉 데이터셋을 활용해 결측치 대체/제거, IQR 및 Z-sco
intjpark.tistory.com
'빅데이터분석기사 실기 | 작업형 1·2·3' 카테고리의 다른 글
| [빅분기 실기] 2유형 (2) 모델링 및 성능평가, 예측값 제출 (0) | 2026.01.22 |
|---|---|
| [빅분기 실기] 2유형 (1) 데이터 전처리, EDA, 모델선정 (0) | 2026.01.21 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (3) - 결측치, 이상치, 중복값 완벽하게 처리하기 (0) | 2026.01.15 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (2) - 필터링, 정렬, 조건부 수정 (0) | 2026.01.14 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (0) | 2026.01.13 |



