
빅데이터분석기사(빅분기) 실기 2유형의 핵심! Iris 붓꽃 데이터셋을 활용한 이진분류(Binary Classification) 문제를 처음부터 끝까지 완벽하게 해결하는 방법을 배웁니다. 결측치·이상치 처리부터 랜덤포레스트(RandomForest) 모델링, 정확도(Accuracy)·F1-Score·AUC 성능평가, 그리고 예측값 제출까지 실전 코드와 함께 상세히 해설합니다. 실기 시험에서 바로 써먹을 수 있는 핵심 팁이 가득합니다!
📌 빅분기 실기 2유형이란?
빅데이터 분석기사 실기 시험의 제2유형은 주어진 데이터셋으로 머신러닝 모델을 구축하고 성능을 평가하는 문제입니다.
2유형 문제의 핵심 5단계:
- 라이브러리 및 데이터 확인
- 탐색적 데이터 분석(EDA)
- 데이터 전처리 및 분리
- 모델링 및 성능평가
- 예측값 제출
오늘은 Iris(붓꽃) 데이터셋을 활용한 이진분류 문제를 통해 이 5단계를 완벽하게 마스터해보겠습니다.
🌸 Iris 붓꽃 데이터셋이란?
Iris 데이터셋은 머신러닝 입문자라면 누구나 한 번쯤 접하는 대표적인 분류 문제 데이터입니다.
데이터 구성:
- 특징(Features): 꽃받침 길이/너비(sepal_length/width), 꽃잎 길이/너비(petal_length/width)
- 타겟(Target): 붓꽃의 종(Species) - Setosa, Versicolor, Virginica 3종
이번 문제의 특징:
- 원래 3개 클래스(다중분류)를 이진분류로 변환
- Setosa 종은 0, 나머지 종(Versicolor, Virginica)은 1로 통합
- 의도적으로 삽입된 결측치와 이상치 처리 필요
1️⃣ 라이브러리 및 데이터 확인
📚 필수 라이브러리 불러오기
import pandas as pd
import numpy as np핵심 포인트:
- pandas: 데이터프레임 조작의 핵심
- numpy: 수치 연산 및 배열 처리
🔧 실기환경 데이터셋 세팅
############### 실기환경 복사 영역 ###############
import pandas as pd
import numpy as np
# 실기 시험 데이터셋으로 셋팅하기 (수정금지)
from sklearn.datasets import load_iris
# Iris 데이터셋을 로드
iris = load_iris()
x = pd.DataFrame(iris.data,
columns=['sepal_length', 'sepal_width',
'petal_length', 'petal_width'])
y = iris.target # 'setosa'=0, 'versicolor'=1, 'virginica'=2
y = np.where(y>0, 1, 0) # setosa 종은 0, 나머지 종은 1로 변경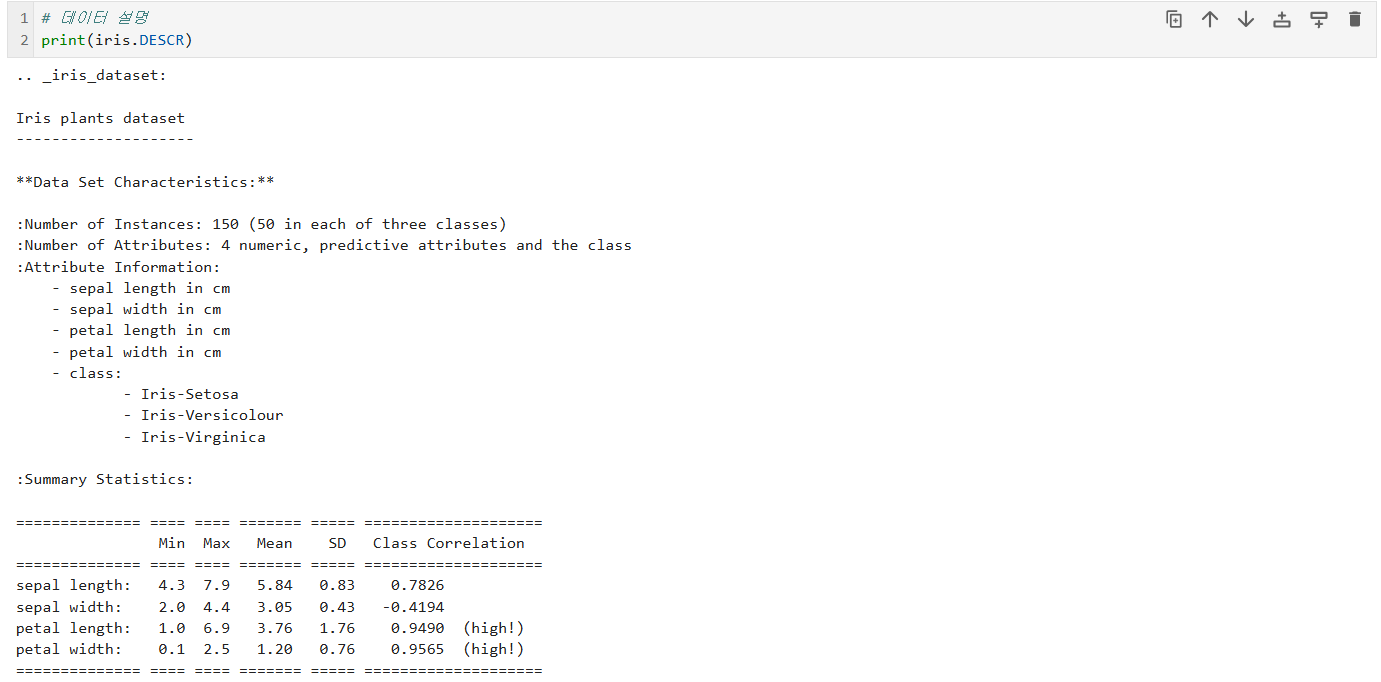
💡 이진분류 변환 코드 해설:
- y = iris.target: 원본은 0, 1, 2 세 가지 클래스
- np.where(y>0, 1, 0): 0보다 크면 1로, 아니면 0으로 변환
- 결과: Setosa(0) vs 나머지(1)의 이진분류 문제로 전환
🔀 Train/Test 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
stratify=y,
random_state=2023
)
x_test = pd.DataFrame(x_test)
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
y_train.columns = ['species']⚠️ stratify 파라미터의 중요성:
- stratify=y: 클래스 비율을 유지하면서 분리
- 이진분류에서 클래스 불균형 문제를 방지
- 실기 시험에서 필수적으로 사용해야 하는 옵션
🚨 결측치·이상치 의도적 삽입
# 결측치 삽입
x_test.loc[x_test.index[0], 'sepal_length'] = None
x_train.loc[x_train.index[0], 'sepal_length'] = None
# 이상치 삽입
x_train.loc[x_train.index[0], 'sepal_width'] = 150
############### 실기환경 복사 영역 ###############🎯 실기 시험 시뮬레이션:
- 실제 시험에서도 이렇게 결측치와 이상치가 포함되어 출제됩니다
- 데이터 전처리 능력을 평가하는 핵심 요소
📝 중요 참고사항
### 참고사항 ###
# y_test는 실기 문제상에 주어지지 않음
# ★Tip: X를 대문자로 쓰지말고 소문자 x로 쓰세요.
# 시험에서 실수하기 쉽습니다.(문제풀기 전에 소문자로 변경!)🔥 실전 꿀팁:
- 변수명은 항상 소문자 x, y 사용 (시험장에서 오타 방지)
- y_test는 실제 시험에서 제공되지 않음
- 2023년 10월 이후 시험 환경 변경사항 숙지 필요
2️⃣ 탐색적 데이터 분석(EDA)
📊 데이터 형태 확인
# 데이터의 행/열 확인
print(x_train.shape) # (120, 4)
print(x_test.shape) # (30, 4)
print(y_train.shape) # (120, 1)
해석:
- 훈련 데이터 120개, 테스트 데이터 30개
- 특징 변수 4개 (꽃받침/꽃잎의 길이/너비)
👀 초기 데이터 확인
# 초기 데이터 확인
print(x_train.head(3))
print(x_test.head(3))
print(y_train.head(3))
확인 포인트:
- 각 컬럼의 데이터 형태
- 수치형 데이터인지, 범주형 데이터인지
- 눈에 띄는 이상한 값이 있는지
🔍 데이터 타입 및 결측치 확인
# 변수명과 데이터 타입이 매칭이 되는지, 결측치가 있는지 확인
print(x_train.info())
print(x_test.info())
print(y_train.info())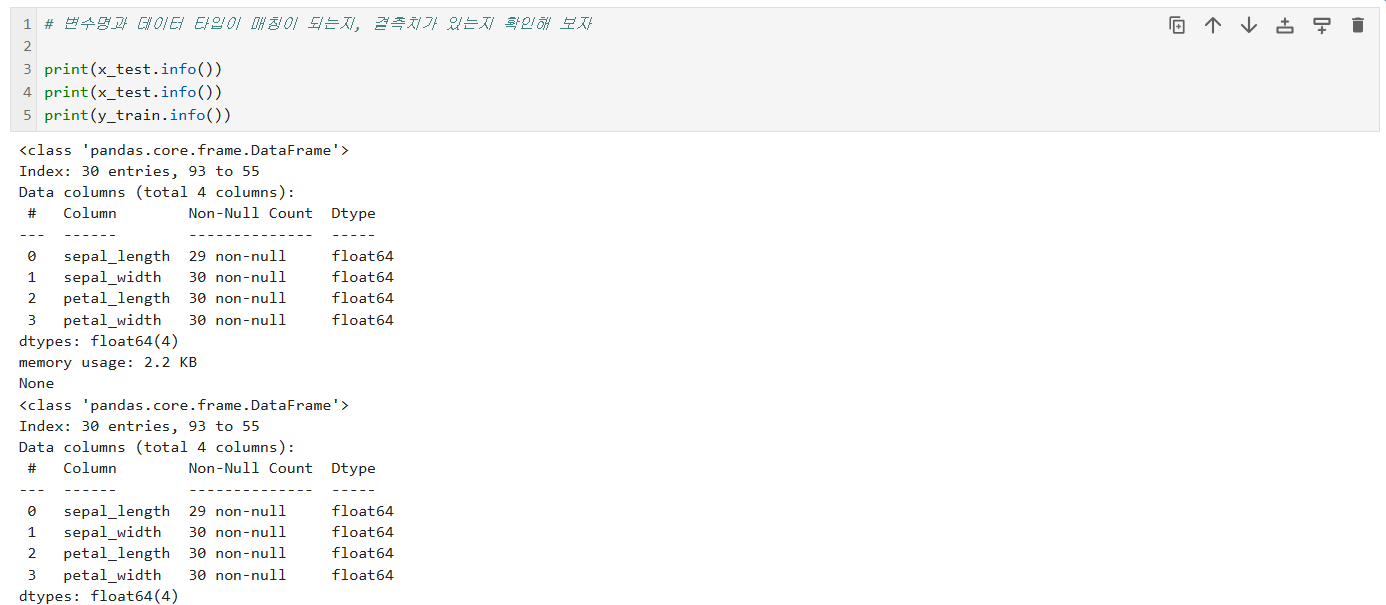
💡 info() 메서드로 확인할 것:
- Non-Null Count: 결측치 개수 파악
- Dtype: 데이터 타입 (float64, int64, object 등)
- Memory usage: 메모리 사용량
📈 기초통계량 비교
# x_train과 x_test 데이터의 기초통계량을 잘 비교해 보세요.
print(x_train.describe().T)
print(x_test.describe().T)
print(y_train.describe().T)
⚠️ describe()에서 발견해야 할 것:
- 이상치: max 값이 비정상적으로 큰 경우 (예: sepal_width가 150)
- 결측치: count 개수가 다른 컬럼들과 다른 경우
- 척도 차이: 변수 간 범위(range)가 크게 다른 경우
🎯 타겟 변수 분포 확인
# y 데이터도 구체적으로 살펴보자
print(y_train.head())
print(y_train.value_counts())

클래스 불균형 체크:
- 0과 1의 개수가 비슷한지 확인
- 심한 불균형이 있다면 모델링 시 추가 조치 필요
3️⃣ 데이터 전처리 및 분리
🔴 결측치 처리
Step 1: 결측치 확인
# 결측치 확인
print(x_train.isnull().sum())
print(x_test.isnull().sum())
print(y_train.isnull().sum())출력 예시:
sepal_length 1 # <- 결측치 발견!
sepal_width 0
petal_length 0
petal_width 0
Step 2: 결측치 대체 전략
# 결측치 대체(중앙값)
# 주의사항: train 데이터의 중앙값으로 test 데이터도 변경해줘야 함
median = x_train['sepal_length'].median()
x_train['sepal_length'] = x_train['sepal_length'].fillna(median)
x_test['sepal_length'] = x_test['sepal_length'].fillna(median)🎯 결측치 대체 방법 선택 가이드:
| 연속형 (대칭분포) | 평균값 | df['col'].mean() |
| 연속형 (왜도 존재) | 중앙값 | df['col'].median() |
| 범주형 | 최빈값 | df['col'].mode()[0] |
⚠️ 핵심 주의사항:
- 반드시 train 데이터의 통계량으로 test 데이터도 처리
- test 데이터는 "unseen data"이므로 독립적으로 계산하면 안 됨
- 이를 데이터 누수(Data Leakage) 방지라고 함
🟠 이상치 처리
Step 1: 이상치 탐지
# 이상치 확인
cond1 = (x_train['sepal_width'] > 10)
print(len(x_train[cond1])) # 1개 발견이상치 판단 기준:
- 도메인 지식 활용 (붓꽃 꽃받침 너비가 150은 비현실적)
- IQR(사분위수 범위) 기법
- 표준편차 기법 (평균 ± 3σ)
Step 2: 이상치 대체
# 이상치를 제외한 Max 값을 구해서 대체
cond1 = (x_train['sepal_width'] <= 10)
max_sw = x_train[cond1]['sepal_width'].max()
print(max_sw) # 정상 범위의 최댓값
x_train['sepal_width'] = np.where(
x_train['sepal_width'] >= 10,
max_sw,
x_train['sepal_width']
)
print(x_train.describe())
💡 np.where() 함수 활용법:
np.where(조건, 참일 때 값, 거짓일 때 값)- 조건: x_train['sepal_width'] >= 10
- 참(이상치): max_sw로 대체
- 거짓(정상): 원래 값 유지
🟢 변수 처리 (필요 시)
# 불필요한 변수 제거
# df = df.drop(columns=['변수1', '변수2'])
# df = df.drop(['변수1', '변수2'], axis=1)
# 필요 시 변수 추가(파생변수 생성)
# df['파생변수명'] = df['A'] * df['B']
# 원핫인코딩(가변수 처리) - 범주형 변수가 있을 때
# x_train = pd.get_dummies(x_train)
# x_test = pd.get_dummies(x_test)
# print(x_train.info())
# print(x_test.info())🔥 실전 팁:
- Iris 데이터는 모두 수치형이므로 원핫인코딩 불필요
- 실제 시험에서 범주형 변수가 있다면 반드시 인코딩 필요
🔵 검증 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(
x_train, # 특징 행렬
y_train, # 타깃 벡터
test_size=0.2,
stratify=y_train, # 계층 샘플링
random_state=2023
)
print(x_train.shape) # (96, 4)
print(x_val.shape) # (24, 4)
print(y_train.shape) # (96, 1)
print(y_val.shape) # (24, 1)❓ 왜 검증 데이터를 따로 분리할까?
- Train: 모델 학습용
- Validation: 모델 성능 평가용 (Accuracy, F1, AUC 계산)
- Test: 최종 예측값 제출용 (정답 없음)
🎯 stratify 파라미터 재강조:
- 클래스 비율을 유지하며 분리
- 불균형 데이터에서 필수
4️⃣ 모델링 및 성능평가
🌲 랜덤포레스트 모델 구축
# 랜덤포레스트 모델 사용 (참고: 회귀모델은 RandomForestRegressor)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(x_train, y_train)
💡 RandomForestClassifier 기본 개념:
- 여러 개의 결정 트리(Decision Tree)를 만들어 투표로 결정
- 앙상블 기법의 대표 모델
- 과적합에 강하고, 성능이 우수함
🔥 회귀 vs 분류 주의:
- 분류(Classification): RandomForestClassifier
- 회귀(Regression): RandomForestRegressor
🎯 예측 수행
# 모델을 사용하여 검증 데이터 예측
y_pred = model.predict(x_val)
predict() 메서드:
- 입력: 특징 데이터 (x_val)
- 출력: 예측 클래스 (0 또는 1)
📊 모델 성능 평가
# 모델 성능 평가 (accuracy, f1 score, AUC 등)
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
acc = accuracy_score(y_val, y_pred) # (실제값, 예측값)
f1 = f1_score(y_val, y_pred) # (실제값, 예측값)
auc = roc_auc_score(y_val, y_pred) # (실제값, 예측값)
# 정확도 (Accuracy)
print(f"Accuracy: {acc:.4f}")
# F1 Score
print(f"F1-Score: {f1:.4f}")
# AUC
print(f"AUC: {auc:.4f}")📈 성능 지표 완벽 이해:
1) Accuracy (정확도)
Accuracy = (TP + TN) / (TP + TN + FP + FN)- 전체 중 올바르게 예측한 비율
- 가장 직관적인 지표
- 단점: 클래스 불균형 시 왜곡 가능
2) F1-Score
F1 = 2 × (Precision × Recall) / (Precision + Recall)- Precision(정밀도)과 Recall(재현율)의 조화평균
- 클래스 불균형 문제에 강건
- 다중분류일 경우: f1_score(y_val, y_pred, average='macro')
3) AUC (Area Under the ROC Curve)
- ROC 곡선 아래 면적
- 0.5~1.0 사이 값 (0.5는 랜덤, 1.0은 완벽)
- 임계값(threshold)에 무관한 평가
🎯 실기 시험 팁:
- 문제에서 요구하는 지표를 정확히 계산
- 보통 Accuracy, F1-Score, AUC 중 1~2개 요구
🔍 혼동행렬(Confusion Matrix) 확인
# 참고사항
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_val, y_pred) # (실제값, 예측값)
print(cm)출력 예시:
[[12 0]
[ 1 11]]해석:
예측 0 예측 1
실제 0 (TN) 12 0 (FP)
실제 1 (FN) 1 11 (TP)- TN (True Negative): 12개 - 0을 0으로 정확히 예측
- FP (False Positive): 0개 - 0을 1로 잘못 예측
- FN (False Negative): 1개 - 1을 0으로 잘못 예측
- TP (True Positive): 11개 - 1을 1로 정확히 예측
5️⃣ 예측값 제출
⚠️ 핵심 주의사항
# (주의) x_test를 모델에 넣어 나온 예측값을 제출해야 함🚨 실기 시험 최다 실수:
- x_val이 아닌 x_test로 예측해야 함
- y_test는 제공되지 않음 (당연히!)
📌 방법 1: 클래스 예측 (predict)
# 1. 특정 클래스로 분류할 경우 (predict)
y_result = model.predict(x_test)
print(y_result[:5])
# 출력: [0 1 1 0 1] - 각 샘플의 예측 클래스predict() 특징:
- 출력: 0 또는 1 (클래스 레이블)
- 문제에서 "분류 결과 제출" 요구 시 사용
📌 방법 2: 확률 예측 (predict_proba)
# 2. 특정 클래스로 분류될 확률을 구할 경우 (predict_proba)
y_result_prob = model.predict_proba(x_test)
print(y_result_prob[:5])
# 출력:
# [[0.92 0.08] <- 0일 확률 92%, 1일 확률 8%
# [0.15 0.85] <- 0일 확률 15%, 1일 확률 85%
# ...]predict_proba() 특징:
- 출력: 각 클래스에 속할 확률 (0~1 사이)
- 문제에서 "확률값 제출" 요구 시 사용
🔍 결과 비교 분석
# 이해해보기
result_prob = pd.DataFrame({
'result': y_result,
'prob_0': y_result_prob[:, 0],
'prob_1': y_result_prob[:, 1]
})
# setosa일 확률: y_result_prob[:, 0]
# 그 외 종일 확률: y_result_prob[:, 1]
print(result_prob[:5])출력 예시:
result prob_0 prob_1
0 0 0.92 0.08
1 1 0.15 0.85
2 1 0.22 0.78
3 0 0.88 0.12
4 1 0.05 0.95💡 해석:
- 첫 번째 샘플: 92% 확률로 클래스 0 → 결과 0
- 두 번째 샘플: 85% 확률로 클래스 1 → 결과 1
💾 최종 제출 파일 저장
# ★ Tip: 데이터를 저장한 다음 불러와 제대로 제출되었는지 확인
pd.DataFrame({'result': y_result}).to_csv('수험번호.csv', index=False)
df2 = pd.read_csv('수험번호.csv')
print(df2.head())🎯 실기 시험 제출 체크리스트:
- 파일명이 수험번호.csv 형식인가?
- 컬럼명이 문제 요구사항과 일치하는가? (보통 'result' 또는 'pred')
- index=False로 설정했는가?
- 제출 전 파일을 다시 불러와 확인했는가?
🎓 빅분기 2유형 완벽 정복 핵심 요약
✅ 반드시 기억해야 할 5가지
- 변수명은 소문자 x, y 사용 - 시험장 실수 방지
- train 통계량으로 test 처리 - 데이터 누수 방지
- stratify 파라미터 필수 사용 - 클래스 비율 유지
- x_test로 최종 예측 - x_val이 아님 주의!
- 제출 전 파일 재확인 - 형식 오류로 0점 방지
🔥 실전 코딩 순서 암기
1. 데이터 로드 → 2. EDA (shape, info, describe, value_counts)
→ 3. 결측치 처리 (fillna) → 4. 이상치 처리 (np.where)
→ 5. 변수 처리 (drop, get_dummies) → 6. 데이터 분리 (train_test_split)
→ 7. 모델 학습 (fit) → 8. 예측 (predict) → 9. 평가 (accuracy, f1, auc)
→ 10. 최종 예측 (x_test) → 11. 제출 (to_csv)📚 성능 지표 선택 가이드
| 클래스 균형 | Accuracy | 직관적이고 간단 |
| 클래스 불균형 | F1-Score | Precision과 Recall 균형 |
| 확률 예측 평가 | AUC | 임계값 무관 평가 |
| 거짓양성 비용 큼 | Precision | FP 최소화 중요 |
| 거짓음성 비용 큼 | Recall | FN 최소화 중요 |
💬 마치며
빅데이터 분석기사 실기 2유형은 단순 암기가 아닌 이해와 실습이 중요합니다.
오늘 배운 Iris 분류 문제를 최소 3번 이상 반복해서 손에 익히세요.
- 1회차: 코드 보면서 따라하기
- 2회차: 해설 보면서 직접 작성
- 3회차: 아무것도 안 보고 처음부터 끝까지
이 흐름이 몸에 배면 어떤 데이터셋이 나와도 당황하지 않고 해결할 수 있습니다.
여러분의 빅분기 합격을 응원합니다! 🎉
https://intjpark.tistory.com/55
[빅분기 실기] 1유형 데이터 다루기 마스터하기
2026 빅데이터분석기사 실기 1유형 완벽 대비! Pandas 전처리, 기초 통계, 그룹연산, 시각화까지 30점 만점 받는 핵심 전략과 실전 코드 예제를 한 번에 정리했습니다. 실기 시험 직전 복습용으로 최
intjpark.tistory.com
https://intjpark.tistory.com/56
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (2) - 필터링, 정렬, 조건부 수정
빅데이터분석기사 실기 1유형 | mtcars로 배우는 필터링·정렬·np.where 파이썬 실습빅데이터분석기사 실기 1유형 대비를 위해 mtcars 데이터셋으로 파이썬 필터링, 정렬, np.where 활용법을 예제 코드와
intjpark.tistory.com
https://intjpark.tistory.com/58
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (3) - 결측치, 이상치, 중복값 완벽하게 처리하기
[빅분기 실기] 04. 데이터 전처리 필살기: 결측치, 이상치, 중복값 완벽하게 처리하기 (Python)설명: 빅데이터분석기사 실기 1유형의 핵심! 타이타닉 데이터셋을 활용해 결측치 대체/제거, IQR 및 Z-sco
intjpark.tistory.com
https://intjpark.tistory.com/60
[빅분기 실기] 1유형 데이터 다루기 마스터하기 (4) 데이터 스케일링, 결합, 그리고 날짜 데이터
주제: 빅데이터분석기사 실기 1유형 대비 데이터 전처리 마스터 (4편)핵심 내용: 데이터 스케일링(표준화/정규화), 데이터 결합(pd.concat), 날짜 및 시간 데이터 처리 기법목표: 실기 시험에서 자주
intjpark.tistory.com
https://intjpark.tistory.com/61
[빅분기 실기] 2유형 (1) 데이터 전처리, EDA, 모델선정
빅데이터분석기사 실기 2유형 합격을 위한 핵심 가이드! 데이터 전처리부터 EDA, RandomForest 모델링, 성능 평가까지 전 과정을 정리했습니다. 실습 코드를 통해 와인 종류 분류 문제를 직접 해결하
intjpark.tistory.com
https://intjpark.tistory.com/62
[빅분기 실기] 2유형 (2) 모델링 및 성능평가, 예측값 제출
빅데이터분석기사(빅분기) 실기 합격을 위한 필수 관문! 랜덤포레스트(RandomForest) 모델을 활용한 머신러닝 모델링 방법과 정확도(Accuracy), F1-score 등 성능 평가 지표를 파이썬 코드로 완벽하게 구
intjpark.tistory.com
https://intjpark.tistory.com/64
[빅분기 실기] 2유형 (3) 회귀 분석 완벽 정복! 당뇨병 데이터 예측 및 모델 평가 (RandomForest)
빅데이터분석기사(빅분기) 실기 제2유형 회귀 모델링을 완벽하게 대비하세요. 사이킷런(Scikit-learn) 당뇨병 데이터를 활용하여 데이터 전처리, 랜덤포레스트 모델링, 성능 평가(MSE, R2) 및 최종 결
intjpark.tistory.com
https://intjpark.tistory.com/65
[빅분기 실기] 2유형 (4) 회귀분석 완벽 정복 (Python 랜덤포레스트 팁 예측)
빅데이터분석기사 실기 시험의 핵심인 제2유형, 그중에서도 회귀분석(Regression) 문제를 대비하기 위한 실전 가이드입니다. Seaborn의 Tips 데이터셋을 활용하여 데이터 탐색(EDA)부터 전처리, 모델링,
intjpark.tistory.com
'빅데이터분석기사 실기 | 작업형 1·2·3' 카테고리의 다른 글
| [빅분기 실기] 2유형 (4) 회귀분석 완벽 정복 (Python 랜덤포레스트 팁 예측) (0) | 2026.02.04 |
|---|---|
| [빅분기 실기] 2유형 (3) 회귀 분석 완벽 정복! 당뇨병 데이터 예측 및 모델 평가 (RandomForest) (4) | 2026.01.24 |
| [빅분기 실기] 2유형 (2) 모델링 및 성능평가, 예측값 제출 (0) | 2026.01.22 |
| [빅분기 실기] 2유형 (1) 데이터 전처리, EDA, 모델선정 (0) | 2026.01.21 |
| [빅분기 실기] 1유형 데이터 다루기 마스터하기 (4) 데이터 스케일링, 결합, 그리고 날짜 데이터 처리 (0) | 2026.01.19 |



